'Database / Sql'에 해당되는 글 90건
- 2009.04.15 [Oracle] 오라클 객체(1) [인덱스(Index)]
- 2009.04.14 [Oracle] PL/SQL에서 엔터(enter)키 역할 사용하는 방법
- 2009.04.14 [Oracle] 테이블 복사
- 2009.03.17 SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램
- 2008.10.21 [Oracle] 통계 함수
- 2008.10.21 [Oracle] 오라클 관련 함수들과 정보들
- 2008.10.21 [Oracle] 함수 모음
- 2008.10.08 SQL의 종류
- 2008.10.08 [Oracle] sid 확인
- 2008.10.08 [Oracle] 오라클이란?
자동 인덱스 : 프라이머리 키 또는 unique 제한 규칙에 의해 자동적으로 생성되는 인덱스 입니다.
수동 인덱스 : CREATE INDEX 명령을 실행해서 만드는 인덱스들 입니다.
※ Index를 생성하는 것이 좋은 Column
- WHERE절이나 join조건 안에서 자주 사용되는 컬럼
- null값이 많이 포함되어 있는 컬럼
- WHERE절이나 join조건에서 자주 사용되는 두 개이상의 컬럼들
※ 다음과 같은 경우에는 index 생성이 불필요 합니다.
- table이 작을 때
- 테이블이 자주 갱신될 때
※ 오라클 인덱스는 B-tree(binary search tree)에 대한 원리를 기반으로 하고 있습니다.
B-tree인덱스는 컬럼안에 독특한 데이터가 많을 때 가장 좋은 효과를 냅니다.
이 알고리즘 원리는
- 주어진 값을 리스트이 중간점에 있는 값과 비교합니다.
만약 그 값이 더 크면 리스트의 아래쪽 반을 버립니다.
만약 그 값이 더 작다면 위쪽 반을 버립ㄴ디ㅏ.
- 하나의 값이 발견될 때 까지 또는 리스트가 끝날 때까지 그와 같은 작업을 다른 반쪽에도 반복합니다.
※ 인덱스는 B-tree 구조를 가지며 크게 다음 네 가지로 분류될 수 있습니다.
1) Bitmap 인덱스
- 비트맵 인덱스는 각 컬럼에 대해 적은 개수의 독특한 값이 있을 경우에 가장 잘 작동합니다. 그러므로 비트맵 인덱스는 B-tree 인덱스가 사용되지 않을 경우에서 성능을 향상 시킵니다. 테이블이 매우 크거나 수정/변경이 잘 일어나지 않는 경우에 사용할수 있습니다.
SQL> CREATE BITMAP INDEX emp_deptno_indx
ON emp(deptno);
2) Unique 인덱스
- Unique 인덱스는 인덱스를 사용한 컬럼의 중복값들을 포함하지 않고 사용할 수 있는 장점이 있습니다. 프라이머리키와 Unique 제약 조건시 생성되는 인덱스는 Unique 인덱스 입니다.
SQL> CREATE UNIQUE INDEX emp_ename_indx
ON emp(ename);
3) Non-Unique 인덱스
- Non-Unique 인덱스는 인덱스를 사용한 컬럼에 중복 데이터 값을 가질수 있습니다.
SQL> CREATE INDEX dept_dname_indx
ON dept(dname);
4) 결합(Concatenated(=Composite)) 인덱스
- 복수개의 컬럼에 생성할 수 있으며 복수키 인덱스가 가질수 있는 최대 컬럼값은 16개 입니다.
SQL> CREATE UNIQUE INDEX emp_empno_ename_indx
ON emp(empno, ename);
** 인덱스의 삭제 **
- 인덱스의 구조는 테이블과 독립적이므로 인덱스의 삭제는 테이블의 데이터에는 아무런 영향도 미치지 않습니다.
- 인덱스를 삭제하려면 INDEX의 소유자이거나 DROP ANY INDEX권한을 가지고 있어야 합니다.
- INDEX는 ALTER를 할 수 없습니다.
SQL> DROP INDEX emp_empno_ename_indx;
※ 인덱스에 대한 정보는 USER_INDEXS 뷰 또는 USER_IND_COLUMNS 뷰를 통해 검색할 수 있습니다.
SQL> SELECT index_name, index_type
FROM USER_INDEXS
WHERE table_name = 'EMP';
INDEX_NAME INDEX_TYPE
--------------------------- -----------
EMP_DEPTNO_INDX BITMAP
EMP_PK_EMPNO NORMAL
| ================================================ * Oracle Community OracleClub.com * http://www.oracleclub.com * http://www.oramaster.net * 운영자 : 김정식 (oramaster _at_ empal.com) ================================================ |
| ※ 강좌를 다른 홈페이지에 기재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^ |
'Database / Sql' 카테고리의 다른 글
| [Oracle] 오라클 객체(3) [SEQUENCE(시퀀스)] (0) | 2009.04.15 |
|---|---|
| [Oracle] 오라클 객체(2) [VIEW 테이블] (0) | 2009.04.15 |
| [Oracle] PL/SQL에서 엔터(enter)키 역할 사용하는 방법 (0) | 2009.04.14 |
| [Oracle] 테이블 복사 (0) | 2009.04.14 |
| SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램 (0) | 2009.03.17 |
Chr(13) : 캐리지 리턴(carriage return)
Chr(10) : 라인피드(new line)
Chr(13)은 동일한 줄의 첫번째 자리에 커서를 위치 (캐리지 리턴)
Chr(10)은 현재 커서가 위치한 곳에서 아래로 한줄 내리는 기능 (라인피드)
예제) replace(text,'\n', chr(13)||chr(10)) -> text에서 \n을 보면 엔터키로 역할 변경
'Database / Sql' 카테고리의 다른 글
| [Oracle] 오라클 객체(2) [VIEW 테이블] (0) | 2009.04.15 |
|---|---|
| [Oracle] 오라클 객체(1) [인덱스(Index)] (0) | 2009.04.15 |
| [Oracle] 테이블 복사 (0) | 2009.04.14 |
| SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램 (0) | 2009.03.17 |
| [Oracle] 통계 함수 (0) | 2008.10.21 |
SELECT한 내용을 INSERT 하기
INSERT INTO CODELIBRARY3 (ID,TYPE,PARENT_ID,NAME,USE_YN,DEL_YN,FLAG)
SELECT * FROM CODELIBRARY T1
테이블 복사
COPY FROM scott/tiger@oracle CREATE emp2 USING select * FROM emp;
CREATE TABLE emp2 AS SELECT * FROM scott.emp;
'Database / Sql' 카테고리의 다른 글
| [Oracle] 오라클 객체(1) [인덱스(Index)] (0) | 2009.04.15 |
|---|---|
| [Oracle] PL/SQL에서 엔터(enter)키 역할 사용하는 방법 (0) | 2009.04.14 |
| SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램 (0) | 2009.03.17 |
| [Oracle] 통계 함수 (0) | 2008.10.21 |
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
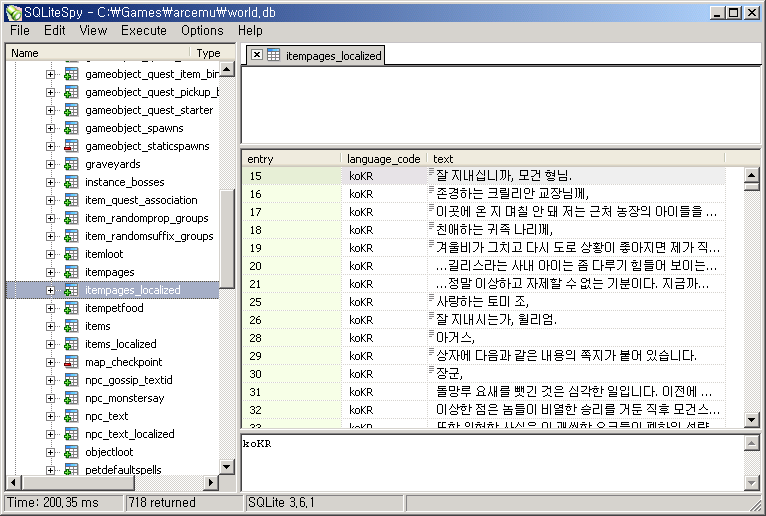
SQL Query문을 알고 있어야 한다는 점을 제외하면 쓸만한 프로그램입니다.
프로그램도 가볍고 DB를 여는데도 큰 시간이 소요되지 않습니다.
다만, 필드 정렬의 경우 상당한 시간이 소요되기에 Select문으로 필요한 부분만 골라내신 다음에
정렬등을 이용하시기 바랍니다.
필드의 값을 수정하실때에는 필드를 선택하신 다음 F2 키를 누르시면
수정을 위한 창이 뜹니다.
* 본 프로그램은 개인 용도에 한해 공개인 프로그램입니다.
출처 : http://arcemu.wowwars.net/forum-f5/topic-t10.htm
'Database / Sql' 카테고리의 다른 글
| [Oracle] PL/SQL에서 엔터(enter)키 역할 사용하는 방법 (0) | 2009.04.14 |
|---|---|
| [Oracle] 테이블 복사 (0) | 2009.04.14 |
| [Oracle] 통계 함수 (0) | 2008.10.21 |
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
1. Ranking Family
(1) RANK() - 상위 순으로 등수를 부여하는 경우 정렬 결과를 기준으로 전체 순위를 출력
☞사용법
RANK() OVER(
[PRTITION BY < value expression1>] [,...]
ODER BY<value expression2> [collate clause] [ASC:DESC]
[NULLS FIRST:NULLS LAST])
OVER : 순위를 부여하기 위한 대상 집합의 정렬 기준과 분할 기준 정의
PARTITION BY : value expression1을 기준으로 분할, 생랼하면 전체 집합을 대상으로 순위부여
ODER BY : 각 분할내에서 데이터를 정렬하는 기준 칼럼 지정
NULLS FIRST|NULLS LAST : 정렬 결과에서 NULL값의 위치 지정
(2) DENSE_RANK() - RNAK함수의 변형 동일 순위를 무시한 연속 순위를 출력
RNAK함수는 1등이 2건인 경우 다음순위를 3등으로 부여 하지만, DENSE_RANK 함수는 다음순위를 2등으로 부여한다.
●
질의
SELECT id,score,
rank()over(ORDER BY score ASC)as rank,
dense_rank() over(order by score asc)as dense_rank
From ksdb_score;
결과
ID SCORE RANK DENSE_RANK
--------- ---------- ---------- ----------
200040394 83 1 1
200020182 88 2 2
200231047 89 3 3
200020182 90 4 4
200020183 90 4 4
200020183 92 6 5
200172058 93 7 6
200040394 95 8 7
(3) CUME_DIST()- 그룹 값 내에서 어떤 값의 cumulative distribution(누적분포)을 계산
☞사용법
CUME_DIST(expr)
(4) PERCENT_RANK()-
(5) NTILE() - 출력결과를 사용자가 지정한 그룹 수로 나누어 출력
☞사용법
NITLE(expr) OVER(
[PARTITION BY< value expression1>][,...]
ORDER BY <value espression2> [collate clause] [ASC : DESC]
[NULLS FIRST:NULLS LAST])
●
질의
SELECT Cid,bday,
NTILE(3) OVER(ORDER BY bday) class
FROM ksdb_customer_info;
결과
CID BDAY CLASS
------ -------- ----------
100004 60/05/02 1
100010 72/08/02 1
100011 74/09/21 1
100006 75/04/05 1
100001 75/07/01 2
100002 77/02/01 2
100007 80/01/04 2
100003 80/01/25 2
100009 81/01/30 3
100005 82/06/01 3
100008 85/04/04 3
11 개의 행이 선택되었습니다.
(6) ROW_NUMBER() - 분할별로 정렬된 결과에 대해 순위를 부여하는 기능 분할은 전체 행을 특정 칼럼을 기준으로 분리하는 기능으로 GROUP BY 절에서 그룹화하는 방법과 같은 개념
☞사용법
ROW_NUMBER() OVER(
[PARTITION BY< value expression1>][,...]
ORDER BY <value espression2> [collate clause] [ASC : DESC]
[NULLS FIRST:NULLS LAST])
●
질의
SELECT id,score,
RANK()OVER(ORDER BY score ASC)as rank,
DENSE_RANK()OVER(order by score asc)as dense_rank,
ROW_NUMBER()OVER(order by score asc)as row_number
From ksdb_score;
결과
ID SCORE RANK DENSE_RANK ROW_NUMBER
--------- ---------- ---------- ---------- ----------
200040394 83 1 1 1
200020182 88 2 2 2
200231047 89 3 3 3
200020182 90 4 4 4
200020183 90 4 4 5
200020183 92 6 5 6
200172058 93 7 6 7
200040394 95 8 7 8
8 개의 행이 선택되었습니다.
↑RANK나 DENSE_RANK에서는 점수가 같으면 순위가 같게4,4 나오지만 ROW_NUMBER에서는 순서대로 4,5 로 번호를 부여한다.
2. Aggregate Family
(1) SUM(), AVG(), MAX(), MIN()
☞사용법
AVG([DISTINCT|ALL] expr)
SUM([DISTINCT|ALL] expr)
expr의 데이터 타입은 NUMBER 데이터 타입만 가능
(2) COUNT() - 테이블에서 조건을 만족하는 행의 개수를 반환
COUNT(*)는 NULL을 가진 행과 중복되는 행을 모두 포함하는 행의 수를 계산
COUNT(expression)는 NULL을 가진 행을 제외한 행의 수를 계산하여 반환
(3) STDDEV() VARIANCE() - 인수로 지정된 칼럼에 대해 조건을 만족하는 행을 대상으로 표준편차와 분산을 구하는 함수로 숫자 데이터 타입에만 사용할 수 있으며, NULL 은 계산에서 제외된다.
(4)RATIO_TO_REPORT()
3. Lead/Lag Family
LEAD() LAG() - 동일한 테이블에 있는 다른 행의 값을 참조하기 위한 함수
LAG 분석함수는 현재 행을 기준으로 이전값을 참조
LEAD 분석함수는 현재 행을 기준으로 이후값을 참조
LEAD LAG 분석함수에서 지정하는 인수는 현재행을 기준으로 몇 번째 행을 참조할 것인지를 지정
음수는 사용할 수 없다.
☞사용법
ROW_NUMBER() OVER(
[PARTITION BY< value expression1>][,...]
ORDER BY <value espression2> [collate clause] [ASC : DESC]
[NULLS FIRST:NULLS LAST])
●
질의
SELECT id,score,
LEAD(score, 1)OVER(ORDER BY score)as next_score,
LAG(score,1)OVER(order by score)as prev_score
From ksdb_score;
결과
ID SCORE NEXT_SCORE PREV_SCORE
--------- ---------- ---------- ----------
200040394 83 88
200020182 88 89 83 ←88 이후 점수 : 89
200231047 89 90 88 88 이전 점수 : 83
200020182 90 90 89
200020183 90 92 90
200020183 92 93 90
200172058 93 95 92
200040394 95 93
8 개의 행이 선택되었습니다.
'Database / Sql' 카테고리의 다른 글
| [Oracle] 테이블 복사 (0) | 2009.04.14 |
|---|---|
| SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램 (0) | 2009.03.17 |
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
| SQL의 종류 (0) | 2008.10.08 |
* Pseudo Column
1) SYSDATE - 날짜
2) ROWNUM - 행의 순서(가상의 숫자, 따라서 where 조건을 쓸 수 없음)
3) ROWID - 모든 행에 대한 식별자의 역할
* 검색 - 오라클 명령어에서 대소문자를 가리지는 않지만, 검색시에는 구분함.
1) select
a) distinct - 중복행제거
b) * - all
c) alias - 해당 컬럼에 다른 이름 부여 : as키워드를 사용하면 명시적이고
따옴표로 묶으면, 대소문자 구분 가능
d) 컬럼값중 숫자형 데이터는 산술연산 가능
e) || - 연결연산자
f) 작은따옴표 - 컬럼에 있는 데이터는 아니지만, 따옴표사이의 내용이 모든 행에 표시된다. 연결연산자와
함께 사용하는 경우가 일반적
2) where - from 절 다음에 와야 한다.
a) and - AND 연산일 경우에는 거짓이 앞에 있는 게 좋고, OR 연산자일 경우에는 참이 앞에 있는 것이 좋다
b) or
c) between ~ and ~ - 이상, 이하의 개념임. 미만, 보다일경우는 부등호 기호 사용
d) in ( 'x', 'y', 'z' )
e) is null / not - NOT이 들어간 SQL 연산자는 사용을 하지 않는 것이 좋다. (ex. NOT IN, IS NOT NULL)
null값으로 들어간 데이터를 확인하는 용도로 쓰인다.
f) like
i) %
ii) _
iii) like 'aa\%%' escape '\'
3) order by 칼럼이름 [asc|desc]
4) group by - 테이블보다 작은 그룹으로 묶어서 값을 얻으려 할 때 사용
a) ROLLUP
b) CUBE
5) having - group by 의 수행결과에 조건을 부여해서 값을 얻으려 할 때 사용
6) grouping sets
a) UNION - 합집합
b) INTERSECT - 교집합
c) MINUS - 차집합
d) UNION ALL - 합집합+교집합
7) subquery - select 문 안에 삽입된 select 문
* SQL함수
1) 단일행함수
a) 숫자
b) 문자
c) 날짜
d) 형변환
e) 기타
2) 집합함수
3) 분석함수
4) 정규표현식
* 숫자함수
1) MOD(m, n) - m을 n으로 나누었을 때의 나머지를 반환
2) ROUND(m, n) - m을 소수점 n+1자리에서 반올림한 결과를 반환
3) WIDTH_BUCKET(대상값, 최소값, 최대값, 버켓수)
4) CEIL(n) - 올림한 후 정수를 반환
5) FLOOR(n) - 내림한 후 정수를 반환
6) ABS(n) - 절대값을 반환
7) TRUNC(m, n) - m을 n자리까지 절삭. n은 생략가능하며, 기본값은 0.
n이 양수이면, 소수자리를 절삭, n이 음수이면, 정수자리를 절삭(= 0으로 만든다)
8) POWER(m, n) - m의 n승값을 반환
9) SQRT(n) - n의 제곱근 값을 반환
10) SIGN(n) - n이 양수인지, 음수인지, 0인지를 반환
11) CHR(n) - 10진수 n의 아스키코드에 해당하는 문자를 반환
* 문자함수
1) LOWER('문자열') - 문자열을 소문자로 반환
2) UPPER('문자열') - 문자열을 대문자로 반환
3) INITCAP('문자열') - 문자열의 첫문자는 대문자로, 나머지 문자는 소문자로 반환
4) CONCAT('문자열1', '문자열2') - 두개의 문자열1과 2를 연결해서 반환. 매개변수는 2개만 가능.
5) SUBSTR('문자열', 시작위치값, 시작위치부터뽑아낼 문자열길이)
6) LENGTH('문자열') - 문자열의 길이를 숫자값으로 반환
7) INSTR('문자열', '표적문자', m, n) - 문자열중에서 표적문자를 왼쪽부터 m번째, m번째부터 n번째
의 위치를 숫자값을 반환
8) LPAD('문자열', 전체문자길이, '나머지문자값') - 전체문자길이중 문자열 길이만큼을 제외한
공간을 왼쪽부터 나머지 문자값으로 채우고, 문자열을 덧붙여서 반환
9) RPAD('문자열', 전체문자길이, '나머지문자값') - LPAD와 동일한 개념인데, 다만, 나머지 문자값을
오른쪽으로 채워서 반환
10) REPLACE('문자열', 'str1', 'str2') - 문자열중에서 str1에 해당하는 문자를 str2의 문자로 바꿔서 반환
11) ASCII('문자') - 문자의 아스키코드값을 반환
12) TRIM('타겟문자' from '문자열') - 문자열중에서 타겟문자를 삭제. 단 문자열의 바깥쪽 문자만이 해당됨.
* 날짜함수
1) MONTHS_BETWEEN(date1, date2) - 두 날짜사이의 월수를 계산해서 숫자로 반환
정수부분은 월을, 소수부분은 일을 의미함.
2) ADD_MONTHS(date1, n) - n이 양수이면, date1에 더해지고, n이 음수이면, date1에서 뺄 값이 됩니다.
3) NEXT_DAY(date1, n) - date1의 날짜를 기준으로, 다음번 n에 해당하는 요일을 반환
ex) NEXT_DAY(sysdate, 'FRIDAY') - 시스템현재날짜로부터 다가올 금요일 날짜를 반환,
NEXT_DAY(sysdate, '금요일') - 시스템이 한글로 설정되어있을 경우, 한글사용도 가능
NEXT_DAY(sysdate, 1) - 숫자1은 일요일, 숫자7은 토요일
cf) 오라클 언어세팅에 의해, 어느 한쪽의 예약어가 거부되는 경우가 있다.
확인방법 : select * from nls_session_parameters;
변경방법 : ALTER SESSION SET NLS_DATE_LANGUAGE = 'AMERICAN';
4) LAST_DAY(date1) - date1날짜가 속한 달의 마지막 날짜를 반환, 윤년,평년은 자동 계산
5) ROUND(date1, 조건) - date1의 날짜를 월단위, 년단위로 반올림처리해서 반환하고, 조건이 없으면,
가장 가까운 날짜로 반올림한다.
ex) ROUND(sysdate, 'MONTH')
ROUND(sysdate, 'YEAR')
ROUND(sysdate)
6) TRUNC(date1, 조건) - date1의 날짜를 가장 가까운 년도 또는 월로 절삭해서 반환. 조건이 없으면,
가장 가까운 날짜로 절삭
* 변환함수
1) 묵시적인 형변환
a) varchar2, char -> number
b) varchar2, char -> date
c) number -> varchar2
d) date -> varchar2
2) 명시적인 형변환
a) TO_CAHR
b) TO_NUMBER
c) TO_DATE
* 기타함수
1) NVL(컬럼명, 원하는값) - 특정컬럼의 null값을 원하는 값으로 변환
2) DECODE(조건, 값1, 처리1, 값2, 처리2, ...... , 디폴트값) - if 분기문과 같은 역할 - 오라클 함수
3) CASE - DECODE함수와 동일한 처리를 한다. 다만 DECODE함수에서 지원하지않는
범위비교가 가능하다. - 표준 SQL
4) NULLIF(m, n) - m과 n이 같으면 null값을 반환하고, 다르면, m을 반환
5) GREATEST - 나열된 값중 제일 큰 값을 반환
6) LEAST - 나열된 값중 제일 작은 값을 반환
* 집합함수 - where 절 사용시 주의
1) AVG - 여러 행으로부터 하나의 결과를 반환
ex) AVG(컬럼명)
ex) AVG(컬럼명) OVER(PARTITION BY 컬럼명)
2) COUNT
3) MAX
4) MIN
5) SUM
6) RANK - 전체값을 대상으로 각 값의 순위를 반환
ex) RANK(값) WITHIN GROUP(ORDER BY 컬럼명)
ex) RANK() OVER (ORDER BY 컬럼명)
[출처] 오라클 설치와 기초 (프로젝트 만들기) |작성자 다덤뵤
'Database / Sql' 카테고리의 다른 글
| SQLiteSpy - 간편한 SQLite3 DB 관리 프로그램 (0) | 2009.03.17 |
|---|---|
| [Oracle] 통계 함수 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
| SQL의 종류 (0) | 2008.10.08 |
| [Oracle] sid 확인 (0) | 2008.10.08 |
-- 숫자 함수 (Number Function)
ABS(n) : 절대값을 계산하는 함수
SQL> SELECT ABS(-10) FROM DUAL; // 결과는 10
CEIL(n) : 주어진 값보다 큰 최소 정수값을 구하는 함수
SQL> SELECT CEIL(5.1) FROM DUAL; // 결과는 6
SQL> SELECT CEIL(-5.1) FROM DUAL; // 결과는 -5
FLOOR(n) : 주어진 값보다 작거나 같은 최대 정수값을 구하는 함수
SQL> SELECT FLOOR(5.1) FROM DUAL; // 결과는 5
SQL> SELECT FLOOR(-5.1) FROM DUAL; // 결과는 -6
EXP(n) : 주어진 값의 e의 승수를 구하는 함수
LN(n) : 주어진 값의 자연로그 값을 구하는 함수
MOD(m, n) : m을 n으로 나우어 남은 값을 반환한다.
SQL> SELECT MOD(5, 3) FROM DUAL; // 결과는 2
SQL> SELECT MOD(5, 0) FROM DUAL; // 결과는 5
POWER(m, n) : m의 n승 값을 구하는 함수
SQL> SELECT POWER(2, 3) FROM DUAL; // 결과는 8
ROUND(m, n) : m 값의 반올림을 구하는 함수. n은 소숫점 자릿수를 명시
SQL> SELECT ROUND(111.126, 1) FROM DUAL; // 결과는 111.1
SQL> SELECT ROUND(111.126, -1) FROM DUAL; // 결과는 110
SIGN(n) : n 값의 부호를 구하는 함수. n > 0일때는 1, n = 0일때는 0, n < 0 일때는 -1
SQRT(n) : n 값의 루트값을 구하는 함수. n은 양수이어야 한다.
TRUNC(n, m) : n 값을 m 소숫점 자리로 반내림한 값을 구하는 함수
SQL> SELECT TRUNC(10.678, 2) FROM DUAL; // 결과는 10.67
SQL> SELECT TRUNC(567.345, -2) FROM DUAL; // 결과는 500
-- 문자 함수 (String Function)
CONCAT(str1, str2) : 두 문자를 합치는 함수. "||" 연산자와 같은 역할을 합니다.
SQL> SELECT CONCAT('Oracle', ' Korea') NAME FROM DUAL; // 결과는 Oracle Korea
INITCAP(str) : 주어진 문자열의 첫 번째 문자를 대문자로 변환시켜 주는 함수
SQL> SELECT INITCAP('junducki') FROM DUAL; // 결과는 Junducki
LOWER(str) : 문자열을 소문자로 변환시켜주는 함수
SQL> SELECT LOWER('JUNDUCKI') FROM DUAL; // 결과는 junducki
UPPER(str) : 문자열을 대문자로 변환시켜주는 함수
SQL> SELECT UPPER('junducki') FROM DUAL; // 결과는 JUNDUCKI
LPAD(str1 , n, str2) : str1 문자열의 왼쪽에 str2 문자열을 str1의 문자열 길이가 n이 되게 채워주는 함수. str1의 문자열이 n보다 클 경우 str1을 n개 문자열 만큼 반환합니다.
SQL> SELECT LPAD('jin', 5, '-') FROM DUAL; // 결과는 --jin
RPAD(str , n, char2) : LPAD와 반대로 오른쪽을 채워주는 함수
SQL> SELECT RPAD('jin', 5, '-') FROM DUAL; // 결과는 jin--
SUBSTR(str, m, n) : str 문자열의 m 번째 자리부터 n개의 문자열을 구하는 함수
SQL> SELECT SUBSTR('junducki', 3, 3) FROM DUAL; // 결과는 ndu
SQL> SELECT SUBSTR('junducki', -3, 3) FROM DUAL; // 결과는 cki
LENGTH(str) : str 문자열의 길이를 구하는 함수
SQL> SELECT LENGTH('junducki') FROM DUAL; // 결과는 8
REPLACE(str1, str2, str3) : str1 문자열에서 str2과 매칭되는 부분을 str3으로 변환하는 함수. 대소문자를 구분함
SQL> SELECT REPLACE('Ukzang ukzang', 'U', 'j') FROM DUAL; // 결과는 jkzang ukzang
INSTR(str1, str2, m, n) : str1 문자열에 str2가 매칭되는 위치를 구하는 함수. m은 str1 문자열의 m 위치에서 부터 검색. n은 매칭되는 횟수를 지정. 매칭되는 것이 없을 때는 0
SQL> SELECTINSTR('junducki junducki', 'u') FROM DUAL; // 결과는 2
SQL> SELECT INSTR('junducki junducki', 'u', 3) FROM DUAL; // 결과는 5
SQL> SELECT INSTR('junducki junducki', 'u', 3, 2) FROM DUAL; // 결과는 11
TRIM(str1, str2) : str1 문자열의 양끝의 str2 문자열을 제거하는 함수, str2를 주지 않으면 [공백]을 제거한다.
LTRIM(str1, str2) : TRIM을 왼쪽 끝만 적용
RTRIM(str1, str2) : TRIM을 오른쪽 끝만 적용
VSIZE(str) : str 문자열의 Byte 수를 구하는 함수. NULL이면 NULL이 반환
SQL> SELECT VSIZe('junducki') FROM DUAL; // 결과는 8
-- 날짜 함수 (Date Function)
LAST_DAY(d) : 달의 마지막 날을 구하는 함수
SQL> SELECT LAST_DAY(SYSDATE) FROM DUAL; // 결과 31-03-2008
ADD_MONTH(m, n) : m의 날짜에 n 달을 더해주는 함수
SQL> SELECT ADD_MONTH(SYSDATE, 2) FROM DUAL; // 결과 24-05-2008
MONTH_BETWEEN(m, n) : m 날짜와 n 날짜 사이의 달수를 구하는 함수
SQL> SELECT MONTHS_BETWEEN(TO_DATE('2008/06/05') , TO_DATE('2008/09/23')) FROM DUAL;
// 결과는 -3.880635
ROUND(d, [f]) : d 날짜를 f로 지정한 단위로 반올림을 구하는 함수
SQL> SELECT ROUND(TO_DATE('2008/08/11'), 'YEAR') FROM DUAL; // 결과는 2009-01-01
SQL> SELECT ROUND(TO_DATE('2008/08/11'), 'MONTH') FROM DUAL; // 결과는 2008-08-01
SQL> SELECT ROUND(TO_DATE('2008/08/11'), 'DAY') FROM DUAL; // 결과는 2008-08-11
날짜에 대한 산술 연산
날짜 + 숫자 : 결과는 날짜. 날짜부터 숫자만큼의 날수가 지난 날짜
날짜 - 숫자 : 결과는 날짜. 날짜부터 숫자만큼의 날수가 전인 날짜
날짜 - 날짜 : 결과는 숫자. 두 날짜의 차이
-- 변환 함수 (Convert Function)
TO_CHAR : DATE형, NUMBER형을 VARCHAR2형으로 변환해주는 함수
SQL> SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD') FROM DUAL; // 결과는 2008/03/28
TO_DATE : CHAR형, VARCHAR2형을 DATE형으로 변환해주는 함수
SQL> SELECT TO_DATE('2008/03/28', 'YYYY/MM/DD') FROM DUAL; // 결과는 2008/03/28
TO_NUMBER : CHAR형, VARCHAR2형을 숫자형으로 변환해주는 함수
SQL> SELECT TO_NUMBER('12327') FROM DUAL; // 결과는 12327
-- 기타 함수 (Etc Function)
NVL : NULL 값을 다른 값으로 변환해주는 함수. 모든 데이터 타입에 사용가능.
SQL> SELECT empno, NVL(comm, 0) FROM emp;
EMPNO NVL(COMM, 0)
----------------------------------------------
7499 300
7521 0
DECODE(value, if1, then1, if2, then2, ...) : 데이터들을 다른 값으로 변환해주는 함수. value 값이 if1일 경우 then1으로, if2일 경우 then2로 ...
SQL> SELECT deptno, DECODE(deptno, 10, 'AAA', 20, 'BBB', 30, 'CCC') FROM emp;
DEPTNO DECODE(DEPT
------------------------------------------------
10 AAA
30 CCC
20 BBB
GREATEST(n1, n2, ...) : 값 중 최대값을 구하는 함수
SQL> SELECT GREATEST(10, -5, 16, 20, -11) FROM DUAL; // 결과는 20
LEAST(n1, n2, ...) : 값 중 최소값을 구하는 함수
SQL> SELECT LEAST(10, -5, 16, 20, -11) FROM DUAL; // 결과는 -11
'Database / Sql' 카테고리의 다른 글
| [Oracle] 통계 함수 (0) | 2008.10.21 |
|---|---|
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| SQL의 종류 (0) | 2008.10.08 |
| [Oracle] sid 확인 (0) | 2008.10.08 |
| [Oracle] 오라클이란? (0) | 2008.10.08 |
DDL(Data Definiton Language) : 데이터와 그 구조를 정의
|
SQL문 |
의 미 |
|
CREATE |
데이터베이스 객체를 생성 |
|
DROP |
데이터베이스 객체를 삭제 |
|
ALTER |
기존에 존재하는 데이터베이스 객체를 다시 정의하는 역할 |
DML(Data Manipulation Language) : 데이터의 검색과 수정 등의 처리
|
SQL문 |
의 미 |
|
INSERT |
데이터베이스 객체에 데이터를 입력 |
|
DELETE |
데이터베이스 객체에 데이터를 삭제 |
|
UPDATE |
기존에 존재하는 데이터베이스 객체안의 데이터 수정 |
|
SELECT |
데이터베이스 객체로부터 데이터를 검색 |
DCL(Data Control Language) : 데이터베이스 사용자의 권한을 제어
|
SQL문 |
의 미 |
|
GRANT |
데이터베이스 객체에 권한을 부여 |
|
REVOKE |
이미 부여된 데이터베이스객체의 권한을 취소 |
'Database / Sql' 카테고리의 다른 글
| [Oracle] 통계 함수 (0) | 2008.10.21 |
|---|---|
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
| [Oracle] sid 확인 (0) | 2008.10.08 |
| [Oracle] 오라클이란? (0) | 2008.10.08 |
select name from v$database;
'Database / Sql' 카테고리의 다른 글
| [Oracle] 통계 함수 (0) | 2008.10.21 |
|---|---|
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
| SQL의 종류 (0) | 2008.10.08 |
| [Oracle] 오라클이란? (0) | 2008.10.08 |
Oracle Corporation이란 미국의 기업에서 만든 데이터 베이스 관리 시스템 입니다.
Oracle 은 Database 에서 가장 많이 쓰이며, 기능 또한 가장 좋은 것으로 알려진 최고의 Database 입니다.
Oracle 을 잘 다룬다고 하면 Database 에 대해서 전문적인 지식을 가지고 있다고 할 만큼
Database = Oracle 라는 인식이 저변에 확대되어 있는 것이 사실입니다.
Microsoft 사의 MS-SQL 버전이 높아지면서 많은 향상된 기능들과 편리한 기능들 그리고 Microsoft 의 OS와 접목된 최적화된 설계로 Oracle 의 시장을 넘보고 있지만 아직까지 Oracle 은 Database 분야에서 선두의 자리를 고수하고 있습니다.
Database 라는 것이 이제는 몰라서는 안 되는 IT 기술의 하나로 되고, 또한 Database 라는 곳이 쓰이는 곳이 많다 보니, DBA 의 중요성은 날로 높아진다고 할 수 있습니다.
이와 함께 많은 사람들이 관심을 갖게된 Oracle의 자격증이 OCP-DBA 자격증입니다.
Database 와 같은 경우는 처음에 공부하기가 조금은 힘든 분야입니다.
용어도 생소하고, 또한 개념 이해도 힘들기 때문에, 처음에 많은 시간을 투자하셔서 공부를 해야 후에 다른 어떤 Database 를 접하게 되어도 접근이 빠릅니다.
사실, Oracle 은 Database 가 복잡하고 많은 기능들이 있다 보니,
처음에 접근하기 힘든 것이 사실입니다만 Oracle DB 를 이해하고 난 다음에
다른 DB 를 공부하는 것은 그만큼 쉬운 것이 사실입니다.
공부를 하시면서 가장 유의할 점은 이해 위주의 공부를 하시라는 것입니다.
Oracle(오라클)
미국 오라클사의 관계 데이터베이스 관리 시스템(RDBMS)의 이름으로.
유닉스 환경에서 사용되는 RDBMS로는 현재 가장 널리 사용되는 대표적인 제품의 하나이다.
검색·갱신용 언어로는 국제 표준화 기구(ISO)에서 표준화한 구조화 조회 언어(SQL)가 표준이 되어 있다. 최신 현행판은 오라클 9i 입니다..
Oracle Corporation == 2000년 6월 기준 ==
1977년 로렌스 J. 엘리슨(Lawrence J. Ellison)이 설립하였다.
본사는 미국 캘리포니아주 레드우드 오라클 파크웨이에 있다.
오라클(Oracle)이란 회사명은 고대 그리스어의 ‘신탁(神託)’에서 유래하였다.
2000년 2월 현재, 97억 달러의 수익을 올려 마이크로소프트(MS)에 이어 세계 제2위 규모의 독립적
소프트웨어 기업으로 성장하였다. 전세계 145개국에 지사가 있으며, 종업원수는 총 4만 3,000명이다.
오라클의 초고속 성장배경에는 인터넷의 무한한 가능성을 예견한 엘리슨 회장의 경영전략이 있다.
그는 인터넷에 오라클의 데이터베이스를 접목시켜, 부담스러운 저장장치 없이도 중앙처리장치(CPU)와 적은 양의 메모리만으로 운영할 수 있는 네트워크 컴퓨터(NC)를 창안함으로써 성장의 발판을 마련하였다.
그 후 오라클은 포스트 PC 시대에 대비한 제품을 잇따라 개발하였다.
마이크로소프트(MS)가 PC 기반에서 절대적인 영향력을 발휘하는 윈도우 운영체계를 만들었다면,
오라클은 인터넷 서버를 통해 정보를 공유하는 포스트 PC 시대에 핵심 기술로 부상한 데이터베이스
분야에서 독보적인 위치를 확보하였다.
오라클의 성장은 인터넷 전자상거래와 깊은 연관이 있다. 1999년 응용프로그램 판매를 통해 4억 4,700만 달러의 매출을 기록했고, 컨설팅과 서비스 수익으로 15억 달러의 수익을 올렸다.
2000년 6월 현재, 기업용 데이터베이스(DB) 분야에서 세계 시장의 절반 이상을 장악하고 있다.
'Database / Sql' 카테고리의 다른 글
| [Oracle] 통계 함수 (0) | 2008.10.21 |
|---|---|
| [Oracle] 오라클 관련 함수들과 정보들 (0) | 2008.10.21 |
| [Oracle] 함수 모음 (0) | 2008.10.21 |
| SQL의 종류 (0) | 2008.10.08 |
| [Oracle] sid 확인 (0) | 2008.10.08 |
 Prev
Prev

 Rss Feed
Rss Feed